1. 서론
현대 소재 개발과 제조 공정 관리에서는 인공지능(AI: Artificial Intelligence)이 혁신 도구로 부상하고 있다. 특히 폴리머 컴파운딩 소재 설계와 플라스틱 사출성형 공정 최적화 분야에서는, 경험과 시행착오에 의존하던 기존 방식에서 벗어나 방대한 데이터와 AI를 활용한 데이터 기반 접근으로의 전환이 빠르게 진행되고 있다.
AI 기술의 본질은 입력 변수 공간에서 출력 결과 공간으로의 대응, 즉 ‘정의역에서 치역으로의 mapping 함수’라고 볼 수 있다. 예를 들어, 소재의 조성이나 공정 조건과 같은 입력을 주면, 물성치나 제품 품질 같은 결과를 예측하는 함수 모델로 작동하며, 복잡한 물리·화학적 관계를 수학적으로 근사하는 대리모델로 활용될 수 있다. 실제로, 사출성형기를 반복 가동하며 얻을 수 있는 결과를 미리 학습된 AI 모델이 빠르게 예측해 줄 수 있다면, 이는 일종의 가상 실험 장치처럼 기능하면서 제품 개발과 생산 공정을 크게 가속화할 수 있다.
이러한 AI 대리모델을 효과적으로 구축하기 위해 서론에서는, 특히 두 가지 핵심 요소를 강조하고자 한다.
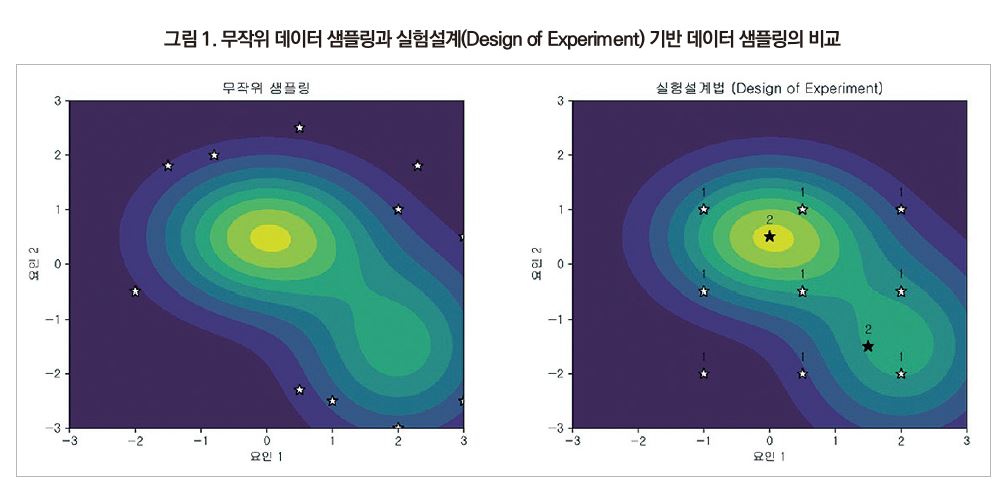
첫째, 도메인 지식과 이를 활용한 데이터 샘플링 전략의 중요성이다. 그림 1과 같이 도메인 지식이 부족한 사람이 아무리 많은 데이터를 수집하더라도, 그 데이터가 성능을 기대할 수 없는 조건에서 수집된 것이라면, 그 학습 데이터로 훈련된 AI 모델은 결코 최적의 사출성형 공정을 도출할 수 없다. 소재와 공정의 설계 공간은 매우 넓고, 실험에는 시간과 비용이 수반되기 때문에 모든 조건을 탐색하는 것은 현실적으로 불가능하다. 따라서 초기 학습 데이터의 선정은 AI 모델의 성능에 큰 영향을 미치며, 무작위 샘플링은 입력 변수 공간 내에서 데이터의 치우침을 야기할 수 있다. 이를 방지하려면 전문가의 경험과 지식을 반영한 실험설계(design of experiment)를 신중히 수행해야 한다. 1, 2
둘째, 이상적인 데이터셋을 확보하기 어려운 현실을 고려할 때, 데이터를 가공하고 보완하는 AI 관련 지식 역시 중요하다. 예를 들어, 공정 조건에 대한 AI 모델이 양품과 불량을 분류하는(classify) 역할을 한다면, 두 클래스 간 데이터 비율이 유사해야 예측 편향을 줄일 수 있다. 3그러나 실제 현장에서는 대개 양품 또는 불량 중 하나가 압도적으로 많아 데이터 불균형 문제가 흔히 발생한다.
4~6 또 다른 예로, 조성이나 공정 조건을 조정하여 제품 성능을 예측하고(regression), 이를 통해 성능을 향상시키고자 하는 경우에는, 고성능 제품에 대한 데이터가 충분히 확보되어야 해당 영역에서의 예측 정확도를 보장할 수 있다. 그러나 현실에서는 대부분 평균적인 성능을 가진 기존 제품의 데이터가 많기 때문에, AI 모델이 고성능 영역을 제대로 학습하지 못하는 문제가 있다. 7 또한 데이터 수집 체계가 부실하거나 노이즈가 많은 경우, 그 데이터를 기반으로 학습된 AI 모델은 오히려 무용지물이 될 수 있으며, 이와 관련된 이상치 탐지와 제거 관련 연구도 활발히 진행 중이다. 8, 9
본 기고문에서는 도메인 지식을 바탕으로 양질의 데이터셋을 구축하고 AI 모델 학습이 가능할 때, 컴파운딩 소재의 설계 및 공정 최적화를 위한 다양한 최적화 및 설계 알고리즘을 어떤 방식으로 적용할 수 있는지, 사출 산업 전반의 실제 사례를 중심으로 설명하고자 한다. 우선 사출 산업의 개요와 국내외 연구 동향을 살펴본 뒤, 컴파운딩 소재에 대한 빅데이터 수집 및 설계 접근법을 소개한다. 컴파운딩 소재의 입력 변수가 너무 많고 생산 가능한 조합이 워낙 다양하다 보니, 아직 균형 잡힌 데이터셋이 충분히 구축되어 있지 않고, featurization도 효율적으로 정립되지 않은 상황임을 함께 서술하고자 한다.
한편, 사출성형 공정 최적화는 상대적으로 유의미한 공정변수의 수가 적고, 데이터 샘플링이 잘 된 사례가 있어, 세 가지 측면에서의 최적화 알고리즘을 소개하고자 한다. 첫째, 같은 장비로 같은 형상의 제품을 생산하더라도 공장의 온도나 습도에 따라 양품 생산 조건이 달라지는 경우가 있는데, 이러한 외부 환경에 적응해 양품 생산이 가능한 공정 조건을 추천해 주는 생성형 AI(generative AI) 기반 연구를 소개한다. 둘째, 시간대나 계절에 따라 변동하는 재료비, 전기가격, 환경 조건에 맞춰 이익을 극대화하는 공정 조건을 찾아내는 강화학습 기반 연구를 다룬다. 마지막으로, AI에 대한 전문 지식이 없는 사람도 효율적으로 AI를 활용할 수 있도록 대형언어모델(LLM)을 접목한 사출 공정 최적화 연구 사례를 소개한다.
2. 사출 산업 전반 및 관련 국내외 연구 동향
2.1 플라스틱 사출 산업의 중요성과 현황
플라스틱 사출 산업은 자동차, 전자제품, 의료기기, 화장품 및 식품 용기 등 생활 전반에서 광범위하게 사용되는 플라스틱 제품을 생산하는 중요한 기초 산업이다. 특히 생활 소재의 약 80%를 차지할 정도로 산업적 비중이 높지만, 여전히 대표적인 3D 업종으로 인식되어 노동력 유입 감소와 낮은 생산성, 높은 산업재해율 등 다양한 문제로 인해 기술 및 경쟁력 향상에 어려움을 겪고 있다.
이러한 문제 중에서도 숙련된 작업자의 경험과 지식이 체계적으로 데이터화되지 못한 채 소멸하면서, 생산 현장에서 품질 관리와 공정 최적화가 점점 더 어려워지고 있다. 자동화 설비가 도입된 생산 현장에서도 여전히 제품 품질은 작업자의 숙련된 지식과 경험에 의존하는 경향이 크다. 그러나 숙련자의 노령화 및 인력의 지속적인 이탈로 인해 숙련된 경험과 지식이 손실되고, 이를 데이터화하지 못한 결과 기술 발전이 정체되는 현상이 발생하고 있다. 이에 따라 제조 경쟁력은 더욱 약화할 수밖에 없는 상황이다.
2.2 플라스틱 사출 산업의 문제점과 이에 대한 해결을 위한 국내외 연구 동향

2.2.1 제품 생산-검사 공정의 수작업으로 인한 생산성 및 품질 저하
플라스틱 사출 제품은 외관 품질에 매우 민감하며, 색상 및 종류가 다양하여 제품 생산 및 품질 검사를 위해 많은 인력이 수작업으로 양품 조건을 탐색하거나 불량 여부를 육안으로 전량 검사하고 있다. 이러한 수작업 방식은 작업자의 숙련도에 따라 품질의 불균일성이 발생하며, 피로 누적으로 인한 생산성 및 정확성 저하의 원인이 되고 있다. 10 이를 해결하기 위하여 LG생활건강, 아모레퍼시픽, 현대자동차, 삼성전자 등 주요 기업들은 무인 품질 검사 시스템을 도입하여 자동화를 추진하고 있으나, 숙련공의 경험에 의존하는 양품 조건 탐색까지 완전 자동화하는 데에는 기술적 한계가 존재하여 추가적인 기술 개발이 요구된다.
2.2.2 숙련공 의존적인 양품 조건 탐색으로 인한 제조 경쟁력 저하 및 재해 위험
플라스틱 사출 공정에서 다양한 형상, 재료 및 환경 조건에 따라 양품 생산을 위한 양산 조건을 설정하는 과정은 전적으로 숙련된 작업자의 경험과 지식에 의존하고 있다. 하지만 숙련자의 지식과 경험이 도제화되지 않아 지속적으로 소실되고 있으며, 신규 작업자의 유입 감소로 인해 제조 경쟁력이 계속 저하되고 있다. 또한, 플라스틱 사출 산업은 화학물질 노출, 고온·고압 환경, 금형 및 프레스 작업으로 인한 산업재해 위험성이 높아 이를 개선할 수 있는 기술 개발이 절실히 요구되고 있다.
2.2.3 국내외 연구 동향
플라스틱 사출 산업의 문제 해결을 위해 국내외 다양한 기관에서 선행 연구가 이루어지고 있다. 세계 최대 플라스틱 사출성형기 제조업체인 독일 Engel 社는 미국의 Autodesk 社와 협력하여 양산 조건을 CAE(Computer-Aided Engineering)로 해석하고, 이를 사출성형기와 직접 연동하는 애플리케이션인 ‘Sim-link’를 개발하였다. 이를 통해 양산 조건을 양방향으로 전송하고 계량, 사출 속도, 보압, 쿠션 등 주요 공정변수를 자동으로 최적화할 수 있으며, 데이터 입력 오류 및 시간 소모를 크게 줄일 수 있다.
국내에서는 정부의 『뿌리 4.0 경쟁력 강화 종합 계획』을 통해 플라스틱 사출 산업이 뿌리산업으로 지정되면서 정책적 지원과 투자가 활발히 진행되고 있다. 대표적으로 국내 최대 사출성형기 제조업체인 우진플라임 社는 고등기술연구원과 협력하여 숙련자의 공정 변경 이력, 외부 환경 데이터, 제품 불량 데이터를 학습하여 엣지 디바이스에서 최적 조건을 자동으로 추론하는 ‘엣지-클라우드 기반 사출성형 공정 지능화 시스템’을 개발하였다.
사출성형기 제조업체 외에도 연구기관 및 학교 등에서는 실제 실험, 시뮬레이션, 데이터 분석 등 다양한 접근법으로 연구를 진행하고 있다. 실제 실험을 통한 선행 연구는 작업자의 반복적인 시도 및 오류(Trial and Error) 문제를 해결하기 위해 실험 계획법에 기반하여 특정 변수를 순차적으로 변경하며 원하는 품질의 조건을 찾는 방식으로 진행되었다. 대표적으로 Huang et al. 11, Wu et al. 12, Kuo et al. 13 등이 다구찌 방법론(Taguchi method)을 활용하여 최적 조건을 찾았으며, Viana et al. 14은 실험 계획법과 ANOVA 통계 분석을 결합하여 충격과 생산 조건 간의 상관관계 및 최적 조건을 결정하는 연구를 수행하였다.
시뮬레이션을 통한 선행 연구는 수지의 유체 흐름 및 열전달을 중심으로 사출품의 불량 여부를 예측하거나, 불량을 방지할 수 있는 양산 조건 도출 및 금형 최적화 연구가 진행되었다. 대표적으로, Seow et al. 15은 각 캐비티(Cavity)로 흐르는 수지량에 따른 불량 가능성을 확인하고, 이를 방지할 수 있는 양산 조건을 확인한 연구를 수행하였다. Smith et al. 16은 금형 형상에 따른 민감도 분석을 수행하여 특정 불량을 방지할 수 있는 최적 금형을 설계하였다.
또한, 시뮬레이션을 통해 특정 생산지표의 최대화 및 최소화를 달성할 수 있는 양산 조건 가능 영역인 프로세스 윈도우(Process window)를 찾는 연구도 수행되었는데, 대표적으로 Seaman et al. 17은 생산 속도를 최대화하면서도 특정 불량을 방지할 수 있는 다목적 최적화(Multi-object optimization) 프로세스 윈도우 탐색 연구를 수행하였다. 생산 데이터 분석을 통한 선행 연구는 인공지능 기술의 확산과 함께 2020년 이후로 본격 진행되었다. 대표적으로, Bensingh et al. 18은 인공신경망(ANN)과 입자 군집 최적화(Particle swarm optimization)를 이용하여 광학 렌즈의 수축 불량을 막을 수 있는 양산 조건 산출 연구를 수행하였다.
Sedighi et al. 19도 인공신경망과 유전 알고리즘(Genetic algorithm)을 활용하여 웰드라인(Weldline) 불량을 최소화할 수 있는 금형 게이트의 위치 최적화 연구를 수행하였다. 그 밖에도 Manjunath et al. 20, Alvarado et al. 21은 제품 변형을 최소화하거나, 또는 Tsai et al. 22, Chen et al. 23, Trovalusci et al. 24과 같이 특정한 기계적 특성을 향상시킬 수 있는 양산 조건 조합을 찾는 연구가 수행되었다.
3.1 빅데이터 현황과 구축 노력
현대 소재 산업은 고성능, 경량화, 지속 가능성을 갖춘 신소재에 대한 수요 증가로 인해 전통적인 실험 기반 접근 방식의 한계를 드러내고 있다. 이러한 한계를 극복하기 위해 빅데이터와 인공지능(AI)을 활용한 소재 개발이 주목받고 있다. AI는 입력과 출력 간의 복잡한 비선형 관계를 효과적으로 모델링할 수 있어, 소재의 구조-특성-성능 간의 복잡한 상호작용을 이해하고 예측하는 데 기여한다. 예를 들어, Google DeepMind의 GNoME(Graph Networks for Materials Exploration)는 Materials Project의 데이터를 활용하여 380,000개의 새로운 안정적인 물질을 예측하였으며, 이는 소재 개발의 속도를 획기적으로 향상시킬 수 있는 가능성을 보여준다. 25
컴파운딩 소재 개발을 위한 데이터베이스 구축은 국내외에서 활발히 진행되고 있다. 대표적인 예로, 미국의 Materials Project는 밀도 범함수 이론(DFT)을 기반으로 약 130,000개 이상의 무기 화합물의 물성 데이터를 제공하여 신소재 개발을 지원하고 있다. 26 또한, 독일의 NOMAD(Novel Materials Discovery) 프로젝트는 계산 및 실험 데이터를 통합하여 FAIR(Findable, Accessible, Interoperable, Reusable) 원칙에 따라 소재 데이터를 공유하고 있으며, 50개 이상의 원자 수준 계산 코드에서 생성된 입력 및 출력 파일을 저장하고 이를 코드 독립적인 형식으로 변환하여 AI 분석에 활용할 수 있도록 지원한다. 27
한국화학연구원(KRICT) 화학 플랫폼 연구본부는 고분자 소재 데이터의 효율적인 관리와 활용을 위해 웹 기반의 플랫폼인 ChemDX(Chemical Data Explorer)를 제공하고 있다. ChemDX 내 MatDX는 소재 데이터 탐색기로, 공개 데이터베이스 및 KRICT와 협력 기관에서 제공한 실험 및 계산 데이터를 통합하여 소재의 물성 정보를 제공한다. ChemAI는 화학 분야에 특화된 인공지능 플랫폼으로, 다양한 예측 알고리즘과 그래프 신경망(Graph Neural Networks)을 활용하여 분자 및 결정 구조로부터 물성 예측 모델을 구축할 수 있다. 이 외에도 신약 개발을 위한 화합물 데이터 플랫폼인 KCB(Korea Chemical Bank)와 화학 혼합물의 독성 예측을 위한 MRA Toolkits를 제공하여 연구자들이 다양한 데이터를 손쉽게 검색하고 활용할 수 있게 한다.
이러한 플랫폼들은 컴파운딩 소재의 설계와 최적화를 위한 기초 자료로 활용되며, AI 기반의 예측 모델 개발에도 중요한 역할을 한다. 예를 들어, 고분자 합성, 가공, 특성 평가, 응용 사례 등의 데이터를 통합하여 AI 모델의 학습 데이터로 활용함으로써, 신소재 개발의 효율성과 정확성을 향상시킬 수 있다. 이러한 노력은 국내외 소재 산업의 경쟁력을 강화하고, 지속 가능한 신소재 개발을 촉진하는 데 기여하고 있다.
3.2 빅데이터를 활용한 소재 최적화 사례
최근 소재 최적화 접근 방식은 소재의 내부 구조를 설계하거나, 또는 조성 및 공정 조건을 조절하여 물성을 향상시키려는 시도로 나뉜다. 이 과정에서 빅데이터와 인공지능(AI)의 활용은 구조–성능 간의 복잡한 비선형 관계를 효과적으로 예측할 수 있는 수단으로 주목받고 있으며, 다양한 분야에서 그 가능성을 입증하고 있다.
첫째는 소재 내부의 구조를 최적화하여 물성을 향상시키는 것으로, 대표적 사례로는 단백질 구조 설계 분야에서의 AI 활용이 있다. RFdiffusion은 확률적 생성 모델(diffusion model)을 기반으로 단백질 구조를 설계하는 모델로, 기존의 구조 예측을 넘어 실제 단백질 기능을 유도하는 3차원 구조를 설계하는 데 성공하였다. 28 이는 고차원 구조 공간에서 목적 기능을 갖춘 분자를 생성하는 AI 기반 소재 설계의 가능성을 보여준다.
또한, Hybrid TPMS 기반 Architectured Materials(HTAM)는 다목적 베이지안 최적화(MBO)를 통해 높은 비강성(stiffness-to-weight ratio)을 갖는 구조를 탐색한 사례로, SLS(Selective Laser Sintering) 및 2PP(Two-Photon Polymerization) 등의 고정밀 3D 프린팅 기술을 통해 이를 실제로 제조하고 기계적 물성 향상을 검증하였다. 29
이외에도, 복합재료 내부의 구성에 따라 파괴 거동을 고려하여 crack propagation 경로까지 설계한 사례도 보고되었다. 30 STGNet이라는 spatiotemporal 모델과 유전 알고리즘(GA)을 결합하여, 복합재료 내부의 균열 전파 경로와 응력 분포를 빠르게 예측하고, 이를 기반으로 고강도·고인성 재료 구조를 역설계하는 데 성공하였다.
둘째는 조성과 공정변수를 조절하여 물성 향상을 위해 AI를 활용하는 것이다. 현재까지 다양한 기계학습(ML) 알고리즘을 활용하여 복합재료의 인장강도, 탄성률, 충격 저항성 등의 물성을 예측하고 최적의 섬유/수지 조합을 도출하는 사례들이 보고되고 있다. 예를 들어, Chang et al. 31은 engineered cementitious composites(ECC)의 인장강도 및 변형률을 예측하기 위해 GEP, GA-ANN, ANFIS 모델을 비교하였고, 실제 혼합물 설계에 대해 실험을 수행하여, 예측과 실측이 거의 일치함을 보였다. Ren et al. 32은 WC 기반 복합 소재의 경도와 파괴인성 예측을 위해 SHAP 기반 ML 프레임 워크를 개발하고, 후보 조성에 대해 실제 진공 소결 실험을 통해 기계적 물성을 검증하였다.
이러한 데이터 기반 접근은 실험 수를 줄이고, 고성능 조성을 신속하게 탐색할 수 있는 장점이 있다. 특히, Bayesian Optimization이나 Multi-objective Optimization 기법과 결합할 경우, 정량적 성능 목표를 동시에 만족시키는 복합 목적 함수를 기반으로 한 조성 설계도 가능해지고 있다. 그러나 조성과 공정은 수십 개 이상의 입력 차원을 가지는 고차원 설계 공간이며, 실험을 통해 결과를 받아보기까지 상당한 시간과 비용이 소요된다. 이러한 제약은 최적화 과정에서 실용적인 장벽으로 작용하고 있으며, 이는 다음 절에서 다룰 현실적인 어려움과 직결된다.
3.3 조성·공정 최적화의 어려움 및 대응 방안
소재의 조성과 공정 조건을 최적화하는 과정에서, 산업계는 여러 현실적인 제약에 직면한다. 특히, 다수의 입력 변수와 출력 변수 간의 복잡한 비선형 관계로 인해, 실험 기반의 최적화는 시간과 비용 측면에서 비효율적일 수 있다. 이러한 최적화 과정에서의 주요 어려움은 다음과 같다:
3.3.1 고차원 입력 변수 공간의 문제
소재의 물성은 다양한 조성 및 공정변수에 의해 결정되며, 이들 변수 간의 상호작용은 비선형적이다. 입력 변수의 수가 증가함에 따라, 전체 설계 공간의 부피는 기하급수적으로 증가하여 데이터의 밀도가 희박해지는 현상이 발생한다. 이러한 현상은 ‘차원의 저주(curse of dimensionality)’로 알려져 있으며, 고차원 공간에서의 데이터 분석과 모델링을 어렵게 만든다. 33 예를 들어, 입력 변수가 2개이고 각 변수에 대해 상한과 하한값을 고려할 경우, 가능한 조합은 22×2=16개이다. 그러나 입력 변수가 10개로 증가하면, 가능한 조합은 22×10=1,048,576개로 급증한다. 이러한 조합의 수는 실험적으로 모두 탐색하기에 현실적으로 불가능하며, AI 기반 대리모델이 입력 공간 전체를 효과적으로 학습하는 데에도 한계가 있다.
이러한 문제를 해결하기 위해서는,
• 물리적 지식과 기존 연구 결과를 활용하여 최적화 대상 변수를 최소화하는 것이 중요하다.
• 변수의 수가 많을 경우, 주성분 분석(Principal Component Analysis, PCA)과 같은 차원 축소 기법을 활용하여 입력 변수의 수를 효과적으로 줄이는 것이 필요하다.
3.3.2 초기 데이터 분포의 적절성 확보
AI 기반 대리모델의 학습과 최적화 성능은 초기 데이터셋의 품질에 크게 의존한다. 초기 데이터가 입력 공간을 고르게 대표하지 못할 경우, 모델의 예측 정확도와 일반화 능력이 저하되며, 최적화 과정에서 비효율이 발생할 수 있다. 무작위 샘플링(Random Sampling, RS)은 구현이 간단하지만, 고차원 공간에서는 샘플이 특정 영역에 집중되거나 중요한 영역이 누락될 수 있다. 이에 따라 일부 영역에서는 예측의 불확실성이 증가하고, 모델의 성능이 저하될 수 있다. 또한, 최적화 과정에서 이러한 누락된 영역을 탐색하기 위해 불필요한 반복이 발생하여 효율성이 감소한다.
이러한 한계를 극복하기 위해 라틴 하이퍼큐브 샘플링(Latin Hypercube Sampling, LHS)이 제안되었다. LHS는 각 입력 변수의 범위를 동일한 확률 간격으로 나누고, 각 구간에서 하나의 샘플을 선택하여 전체 입력 공간을 균일하게 탐색할 수 있도록 한다. 최근 연구에서는 LHS가 RS에 비해 예측 정확도와 모델의 일반화 능력에서 우수한 성능을 보였으며, 특히 고차원 공간에서의 효율적인 샘플링 방법으로 주목받고 있다. 34 따라서, 초기 데이터셋을 구성할 때는 LHS와 같은 균일한 샘플링 기법을 활용하여 입력 공간 전반을 고르게 대표하는 데이터 포인트를 확보하는 것이 중요하다. 이는 AI 대리모델의 학습 효율성을 높이고, 최적화 과정에서의 반복 횟수를 줄이며, 전체적인 최적화 성능을 향상시키는 데 기여할 수 있다.
3.3.3 최적화 과정에서의 효율적 후보군 추출
전통적으로 소재 성능 개선을 위한 후보 조합의 선정은 경험적(Trial and error) 방법과 유전 알고리즘 기반의 최적화 기법에 의존해 왔다. 그러나 각 방법은 시간과 비용이 많이 소요되며, 탐색(exploration) 보다는 활용(exploitation)에 중점을 둔 방법들로 전역 최적점을 찾기 위해 많은 반복이 요구된다는 단점이 있다.
이에 대한 대안으로 베이지안 최적화(Bayesian Optimization)가 제안되었다. 베이지안 최적화는 확률적 모델을 기반으로 하여, 실험이나 시뮬레이션을 통해 얻은 데이터를 활용하여 다음 실험에서 가장 유망한 후보를 선택하는 방법이다. 35 베이지안 최적화의 핵심은 획득 함수(acquisition function)이며, 그중에서도 기대 향상(Expected Improvement, EI)은 현재까지의 최적 결과보다 얼마나 개선될 수 있는지를 확률적으로 평가하여 후보를 선택한다. EI는 탐색(exploration)과 활용(exploitation) 사이의 균형을 유지하여, 최소한의 실험으로도 빠르게 향상된 조성 및 공정 조건을 찾을 수 있도록 한다.
조성 및 공정 조건의 최적화는 고차원 입력 변수 공간, 초기 데이터 분포의 적절성, 후보군 선정의 효율성 등 여러 어려움이 존재한다. 그러나 물리적 지식과 기존 연구 결과를 활용하여 최적화 대상 변수를 최소화하고, 효율적인 샘플링 및 최적화 기법을 적용함으로써, 시간과 비용 측면에서 효율적인 최적화를 달성할 수 있다.
4. 생성 AI 기반 사출 공정 설계
4.1 생성 AI 기반 사출 공정 설계 시스템의 필요성
현대 제조업에서 플라스틱 사출성형 공정은 자동차, 전자기기, 의료기기, 화장품 용기 등 생활 전반에 필수적인 제품들을 대량 생산하는 핵심 기술이다. 그러나 이 공정의 최적화는 지금까지 주로 숙련된 작업자의 경험과 반복적인 시행착오에 의존해 왔으며, 이는 높은 생산 비용과 불균일한 품질 관리의 주된 원인이 되고 있다. 특히 플라스틱 사출성형은 복잡한 공정 파라미터와 외부 환경 변화에 민감하기 때문에, 전통적인 방식으로는 일관된 품질을 보장하는 것이 어려운 실정이다.
최근 제조업에서는 이러한 문제를 해결하기 위해 인공지능(AI)을 활용한 데이터 기반 접근법이 빠르게 부상하고 있다. AI 기술은 입력 변수(예: 공정 조건, 소재 조성)와 출력 결과(예: 제품 품질)의 복잡한 관계를 효과적으로 학습하고, 실시간으로 공정 조건을 최적화하여 생산성을 높일 수 있는 잠재력을 갖고 있다. 특히 AI 기반의 모델은 기존의 반복적이고 시간 소모적인 실험을 대체할 수 있는 가상 실험 환경으로 기능하여, 공정 최적화 과정의 효율성을 크게 향상시킬 수 있다.
하지만 AI 모델이 충분한 성능을 발휘하기 위해서는 고품질의 학습 데이터가 필수적이다. 기존의 무작위 데이터 수집 방식은 입력 변수 공간 내에서 편향된 데이터 분포를 초래할 수 있으며, 이는 AI 모델의 예측 정확도를 저하시킬 수 있다. 따라서 전문가의 도메인 지식과 체계적인 실험설계(Design of Experiment, DOE)를 기반으로 한 데이터 수집이 중요하다.
본 연구는 이러한 DOE 기반 데이터 수집 방법을 활용하여 플라스틱 사출성형 공정의 비효율성과 불균일한 품질 문제를 해결하고자 한다. 구체적으로는 확산(diffusion) 모델을 이용한 자동 공정 조건 추론 시스템을 개발하여, 숙련된 작업자의 경험에 의존하지 않고도 외부 환경 조건 변화에 실시간으로 대응하여 양품을 일관되게 생산할 수 있는 공정 최적화를 목표로 한다. 이를 통해 AI 기반의 사출성형 공정 최적화가 생산성 향상과 품질 안정성 확보에 실질적으로 기여할 수 있음을 검증하고, 제조업 전반에서 데이터 기반 의사결정 시스템 구축의 중요성을 제시하고자 한다.
4.2 양품 공정변수 추천 시스템 개요
그림 7은 사출 공정에서 양품 생산을 위한 최적의 공정변수를 추천하는 시스템의 구성도이다. 시스템은 다음과 같이 데이터 수집, 품질 예측 모델 구축, 공정변수 추천 모델 구축, 실험 검증 단계로 구성된다:
1) 데이터 수집 단계에서는 인공지능을 학습하기 위한 최적의 데이터셋 구성을 목표로 한다. 데이터 수집을 위한 시험대(testbed)는 온·습도 센서, 중앙모니터링시스템(CMS), 비전 검사기를 갖춘 자동화 라인으로 구성된다. 온·습도 센서는 사출기 및 공장 내 환경을 1분 단위로 수집하며, 공정변수 43종 중 작업자가 실제 변경하는 10개 핵심 변수(3단계 속도·압력·위치 각 3개, 보압 시간 1개)를 선별했다. 제품 품질은 내경 허용오차(48.6-48.9㎜) 및 외관 결함(단발·숏샷·용접선)을 기준으로 양품과 불량을 구분하였다. 실험 계획법(Design Of Experiment)을 활용하여 총 2,794개의 실험 데이터를 획득하였으며, 데이터셋은 공정변수 및 환경 변수-품질 데이터로 구성된다.
2) 최적의 대리모델 개발 단계에서는 수집된 데이터셋을 기반으로 공정변수 및 환경 변수로부터 품질을 예측하는 인공지능 모델을 개발한다. 개발된 모델은 사출성형기를 대신하는 가상 실험 장치 역할을 수행한다.
3) 확산과정에서는 주어진 환경 조건에서 양품 생산을 위한 공정변수를 추천하는 확산모델을 구축하고 훈련한다.
4) 가상 실험 단계에서는 훈련된 확산모델로부터 주어진 환경 조건에서의 양품 공정변수들을 추론하고 이를 2)에서 구축한 대리모델로 1차 검증한다. 이로써 양품을 생산하지 않는 것으로 추론되는 공정변수들을 1차적으로 걸러낸다.
5) 실험 검증 단계에서는 정제된 양품 공정변수를 실제 사출기에 입력하여 양품이 나오는지 여부를 판단한다. 이 단계를 통해 구축된 시스템의 현장 적용 가능성을 확인한다.
그림 8의 a에서는 구축한 대리모델의 10겹 교차검증 결과, b에서는 구축한 대리모델의 테스트 데이터셋에 대한 예측 성능, c에서는 공정변수와 품질 간의 상관관계 분석(상단 그래프) 및 양품을 생산하는데 각 공정변수의 기여도(하단 그래프)를 나타낸다. 그림 8a는 대리모델의 일반화된 예측 성능을 평가하기 위하여 수행한 10겹 교차검증 결과이다. 정확도 0.990±0.008, AUC 0.964±0.019, 진양성률(TPR, 대리모델이 실제로 불량인 데이터를 정확히 불량이라고 예측한 비율) 0.927±0.066, 진음성률(TNR, 대리모델이 실제로 양품인 데이터를 정확히 양품이라고 예측한 비율) 0.995±0.006으로 4개의 성능지표 모두에서 92% 이상의 예측 성능을 보이며 대리모델의 우수한 예측 성능을 나타낸다. 양품과 불량에 대한 각각의 예측 성능 또한 높은 정확도를 보이며, 균형 잡힌 예측 성능을 보인다.
그림 8b는 대리모델의 테스트 데이터에 대한 예측 성능을 보여준다. 양품 클래스 259개 중 1개를 틀리고, 불량 클래스 21개 중 1개를 틀리는 결과를 보여주며 우수한 예측 성능을 입증한다. 이로써, 구축한 대리모델이 사출성형기를 대신할 수 있는 가상실험기 역할을 할 수 있음을 보인다. 그림 8c의 상단 그래프는 공정변수와 품질 간의 상관관계를 보여주는 그래프이다. 예를 들어, 사출 속도3은 값이 작아질수록 불량일 가능성이 높음을 의미하며, 사출 위치2는 값이 커질수록 양품일 가능성이 높음을 의미한다. 해당 분석 결과는 사출 업자에게 공정변수 조절에 대한 가이드 라인을 줄 수 있다. 그림 8c의 하단 그래프는 양품 생산에 대한 각 공정변수의 기여도를 보여준다. 상단에 있는 공정변수일수록 양품을 생산하는 데 중요한 역할을 한다. 해당 분석 결과는 불량이 발생했을 때 조절할 수 있는 다양한 공정변수 중 어떤 공정변수를 먼저 조절해야 할지에 대한 가이드 라인을 줄 수 있다.
4.4 양품 공정변수 추론모델의 성능 비교
그림 9는 세 가지 인공지능 모델이 생성한 양품 공정변수들을 구축된 대리모델에 입력하여 가상 실험을 한 결과를 보여준다. “오차 맵” 열을 통해 각 인공지능 모델의 오차를 정성적으로 확인할 수 있으며, “혼동 행렬” 열을 통해 오차의 정량적인 평가까지 확인할 수 있다. 세 가지 양품 공정변수 추론모델 중에서 CFGDM(Classifier-Free Guidance Diffusion Model, 분류기 비 의존도 유도 확산모델)이 가장 적은 오차를 보여줬으며, 양품 공정변수 추론모델로써 가장 신뢰도 있는 모델임을 확인하였다.
그림 10은 주어진 환경 조건과 품질 조건에 대해 공정변수 추론모델(CFGDM 모델)이 제안한 공정변수를 실제 사출기에 입력했을 때 나온 제품의 품질 결과이다. 4번의 실험을 진행하였으며, 그림 10a는 현재 환경 조건에서 양품을 생산하는 공정변수들을 추론해달라고 했을 때, 그림 10b는 현재 환경 조건에서 불량을 생산하는 공정변수들을 추론해달라고 했을 때 나온 공정변수들을 실제 사출기에 입력하여 품질을 확인하였다.
그림 10a에서는 CFGDM 모델에 의해 추론된 양품 공정변수 중 2개만이 불량품을 생산하는 결과를 보인다. 불량이 나온 두 개의 공정변수를 구축된 대리모델에 입력해 보면, 양품일 확률이 각각 96.9%, 98.5%가 나오며 이 값들은 다른 양품 공정변수들의 양품일 확률과 비교했을 때 다소 낮은 값을 보여준다. 이는 사용자가 99% 이상의 확률을 가진 공정변수만 선택해 사용함으로써 신뢰성을 높일 수 있음을 시사한다. 그림 10b에서는 CFGDM 모델에 의해 추론된 불량 공정변수가 모두 불량품을 생산하는 결과를 보인다. 이 결과는 모델의 신뢰성을 확인하기 위한 절차로써, CFGDM 모델이 적절히 훈련되어 높은 신뢰성을 갖음을 보여준다.
5. 강화학습 기반 공정 제어
5.1 강화학습 기반 실시간 공정변수 최적화의 필요성
플라스틱 사출성형 공정은 다양한 제품에 대해 고품질을 유지하면서도 높은 생산성과 경제성을 동시에 달성해야 하는 복잡한 제조 과정이다. 특히, 공정변수(예: 압력, 속도, 온도 등)는 제품 품질뿐 아니라 생산 주기, 전력 소비, 금형 마모 등 생산 비용에 직결되므로 정밀한 제어가 필수적이다. 그러나 기존의 공정변수 설정은 대부분 품질 확보에 초점을 맞추고 있어, 전력 요금이나 원재료 가격처럼 시간 및 환경에 따라 변화하는 비용 요인을 반영하지 못한다. 이에 따라 제품은 양호하더라도 생산 효율성과 수익성 측면에서는 최적화되지 않는 문제가 발생한다.
심층 강화학습(Deep Reinforcement Learning, DRL)은 이러한 문제에 대응하기 위한 효과적인 접근법을 제공한다. DRL은 환경으로부터의 피드백을 통해 최적 정책을 학습할 수 있어, 공정 조건뿐 아니라 실시간으로 변동하는 전력 요금, 온도 및 습도 등 외부 요인까지 반영한 공정변수 제어가 가능하다. 이를 통해 기존에 고정된 최적화 방식이 갖는 한계를 극복하고, 제품 품질을 유지하면서도 전력 및 금형 비용을 최소화하는 방향으로 실시간 공정 조정을 수행할 수 있다. 특히, DRL 기반 의사결정 모델은 학습이 완료된 이후 매우 짧은 시간 내에 최적 조건을 산출할 수 있어, 실제 산업 현장에서 실시간적용이 가능하다는 점에서 높은 활용 가능성을 가진다.
5.2 강화학습 기반 실시간 공정변수 최적화 프레임워크의 전체 구조 개요
그림 11은 심층 강화학습을 활용하여 환경 변화에 따라 실시간으로 공정변수를 최적화하는 의사결정 구조를 나타낸다. 해당 구조에서는 학습된 에이전트가 대리모델을 기반으로 품질과 비용 요소를 동시에 고려하며 공정 조건을 최적화한다. 먼저 데이터 수집 단계에서는 실제 사출성형 공정에서 수집된 데이터를 바탕으로 오프라인 심층 강화학습을 위한 대리모델 학습용 데이터셋을 구축한다. 수집된 데이터는 공정변수 43종 중 실제 현장 작업자가 조작할 수 있는 10개의 핵심 변수, 사출기 및 공장 내 온도·습도 등의 환경 변수, 내경 기준과 외관 결함에 따른 양품 또는 불량 여부로 구성된 품질 정보, 그리고 생산 시간을 나타내는 사이클 타임 등으로 구성된다. 실험 계획법을 활용하여 총 2,794개의 실험 데이터를 확보하였으며, 구축된 데이터셋은 공정변수와 환경 변수, 품질 정보, 사이클 타임으로 구성되어 있다.
이후 심층 강화학습 기반의 의사결정 모델 학습 단계에서는 앞서 수집된 학습 데이터를 활용하여 품질 분류 및 사이클 타임 예측을 위한 대리모델을 학습한다. 이 대리모델은 강화학습 에이전트가 상호 작용하는 가상 사출성형 환경으로 활용되며, 에이전트는 PPO(Proximal Policy Optimization) 및 SAC(Soft Actor-Critic) 알고리즘을 통해 온도, 습도 등 환경 변수의 변화에 유연하게 대응할 수 있도록 공정변수 조정 정책을 학습한다.
마지막으로 실시간 최적화 단계에서는 학습된 강화학습 에이전트를 실제 생산 환경에 배치하여, 온도, 습도, 전력 단가 등 외부 조건을 실시간으로 반영하면서 공정변수를 조정한다. 이를 통해 양품 생산을 안정적으로 유지함과 동시에 에너지 및 생산 비용을 절감하고, 궁극적으로는 공정의 수익성을 극대화할 수 있다.
5.3 강화학습 기반 실시간 공정변수 최적화 방법의 수익성 및 계산 시간 비교
그림 12는 계절에 따른 환경 변수와 전력 요금의 변화를 시각화하고, PPO, SAC 기반 의사결정 모델과 Genetic Algorithm(GA) 기반 최적화 기법을 실제 생산 환경에 적용했을 때의 수익성과 계산 시간을 비교한 결과를 보여준다. 그림 12(a)~(c)는 사출성형 공정에 영향을 미치는 계절별 온도 변화와 시간대별 전력 요금 변화를 시각적으로 나타낸 것이다. 이러한 외부 조건은 생산 단가, 품질 안정성, 에너지 소비에 직접적인 영향을 주며, 공정 최적화 시 반드시 고려되어야 할 요소이다. 강화학습 기반의 에이전트는 이와 같은 환경 변화에 대응할 수 있도록 학습되며, 외부 조건을 실시간으로 반영해 최적의 공정 조건을 결정할 수 있도록 설계되었다.
그림 12(d)는 사전에 학습된 PPO, SAC 의사결정 모델과 GA 최적화 기법을 동일한 환경에 적용하여 수익성과 계산 시간을 비교한 결과를 나타낸다. 실험 결과, PPO와 SAC는 GA와 유사한 수준의 수익성을 유지하면서도, 계산 시간 측면에서는 GA 대비 수십 배 이상 빠른 처리 속도를 보여주었다. 특히 SAC는 환경 변화에 대한 적응력과 안정적인 성능을 바탕으로 보다 일관된 결과를 제공했으며, 실시간 공정 제어에 적합한 특성을 확인할 수 있었다. 반면 GA는 탐색 성능은 우수하였으나 반복적인 연산이 요구되어 계산 시간이 길고, 실시간적용에는 한계가 있는 것으로 나타났다.
이러한 비교 결과는 강화학습 기반 의사결정 모델이 실제 생산 환경에서 환경 조건 변화에 즉각적으로 대응할 수 있으며, 계산 효율성까지 확보할 수 있다는 점에서 기존 최적화 기법보다 우수한 대안임을 보여준다. 특히 실시간 제어와 운영 효율성이 중요한 제조 현장에서, PPO와 SAC는 수익성과 속도 두 측면에서 균형 잡힌 성능을 제공하며, 향후 공정 자동화 및 지능형 운영 시스템에 효과적으로 활용될 수 있을 것으로 기대된다.
6. LLM 기반 사출 공정 구동 UI
6.1 LLM 기반 사출성형 지식 전이 시스템의 필요성
사출성형은 고정밀 플라스틱 부품을 대량 생산하는 대표적인 제조 방식으로, 다양한 산업에서 핵심적인 생산 공정으로 자리 잡고 있다. 특히, 고 다품종 소량 생산(high-mix, low-volume)이 일반화되면서, 생산 조건의 복잡성과 외부 환경 변화에 따라 작업자들의 고도 현장 지식이 필수적으로 요구되고 있다. 현재까지의 사출성형 공정은 숙련자의 경험에 기반한 수작업 판단에 크게 의존하고 있으며, 재료 특성, 금형 상태, 장비 세팅 등 다양한 변수가 제품 품질에 직접적으로 영향을 미친다.
기존의 지식 전이 방식은 문제별 규칙 정리, 고장 대응 매뉴얼 작성, 숙련자-비숙련자 간 도제식 교육 모델에 기반해 왔으나, 최근 고령화와 신규 인력 유입 감소로 인해 산업 현장의 노하우 단절이 심화되고 있다. 특히 다국적 생산 환경에서는 언어 장벽 또한 지식 공유를 어렵게 만들고 있으며, 이에 따라 생산 품질 저하와 효율성 저하로 이어지는 사례가 증가하고 있다. 따라서, 숙련자의 암묵지를 체계적으로 문서화하고, 다양한 언어와 숙련도 수준의 작업자 간 원활한 소통이 가능한 지능형 지식 전이 시스템의 구축이 요구되고 있다.
6.2 LLM의 산업 적용 발전 현황
최근 대규모 언어 모델(Large Language Models, LLM)의 비약적인 발전은 자연어 추론, 문제 해결, 맥락 기반 판단 등에서 인간 수준의 성능을 보이며, 다양한 산업 분야에서 응용 가능성을 보여주고 있다. 특히, Chain-of-Thought prompting, In-context learning과 같은 기술은 모델 파라미터를 수정하지 않고도 복잡한 문제를 단계적으로 해석하고, 제한된 예시만으로도 유의미한 판단을 수행할 수 있도록 한다.
하지만 일반적인 프롬프트 기반 LLM은 특정 산업 도메인에 대한 이해가 부족하고, 비사실적 내용(hallucination)을 생성하는 한계가 존재한다. 이러한 한계를 극복하기 위해, 특정 태스크에 맞춘 파인튜닝(fine-tuning), 외부 지식 기반 정보를 동적으로 삽입하는 검색 기반 생성(Retrieval-Augmented Generation, RAG), 그리고 도구 기반 LLM 에이전트(agent)의 개발이 활발히 이루어지고 있다. 최근에는 다중 LLM 에이전트가 역할을 분담하고 상호 협력하여 복잡한 작업을 수행하는 멀티 에이전트 프레임 워크로 발전하고 있으며, 이는 제조 현장에 요구되는 유연하고 상황 적응적인 AI 시스템 구현에 적합한 방식으로 주목받고 있다.
6.3 LLM 기반 사출성형 지식 전이 프레임 워크의 전체 구조 개요
본 연구에서는 복잡한 사출성형 현장 지식 전이를 위한 멀티 에이전트 LLM 기반 프레임 워크를 제안한다. 그림 13과 같이 본 프레임 워크는 다양한 도구(tool)와 지식 소스를 연동한 다중 LLM 에이전트 시스템으로 구성되며, 입력된 작업자의 업무를 처리하기 위해 계획–수행–평가의 단계를 통해 자율적으로 응답을 생성한다.
구체적으로, 작업자의 질의가 입력되면, 시스템은 과거 대화 기록을 참조하여 맥락 정보를 재구성하고, 번역 및 분류를 입력 처리한다. 이후, 사출성형 관련 질의는 “계획-실행 워크플로”에 따라 순차적으로 해결되며, 이를 위해 다음의 네 가지 도구들이 사용된다: (1) 인터넷 검색 모듈, (2) 고장 대응 테이블 검색기, (3) 제조 메뉴얼 검색기, (4) 디퓨전 모델. 이 중 (2)~(3)은 제한된 정적 지식 기반을 활용하는 반면, (4)는 현장 데이터를 기반으로 공정 조건을 정량적으로 생성한다. 사출성형과 관련이 없는 업무의 경우에는 계산의 자원을 아끼고, 빠른 답변을 위해서 계획 및 실행을 건너뛰고, 하나의 에이전트(ReAct 에이전트)가 추론 및 인터넷 검색을 진행하여 답변하는 방식으로 답변을 생성한다. 이러한 구조는 제한된 도메인 지식과 풍부한 실측 데이터 기반 문제에 각각 대응할 수 있는 동시에, 일상적으로 어렵지 않는 문제에 대해서는 빠른 답변을 가능하게 한다. 마지막으로, 사용자의 질의는 다국어로 입력될 수 있고, 최종 응답은 해당 언어로 자동 번역되어 반환된다.